币安Binance交易所_全球最大交易量的数字平台app
币安Binance交易所_全球最大交易量的数字平台app来源:TOP创新区研究院
作者:创新区研究组
随着ChatGPT的问世,我们正见证着新一轮的人工智能革命。这场革命不仅改变了人类与机器、技术与产业、虚拟与现实之间的关系,而且对人类社会文明秩序带来了深刻的挑战。
而要抓住这些机遇,或是迎接潜在的挑战,不仅取决于技术能力,也取决于你“在哪里”。
 旱的旱死,涝的涝死
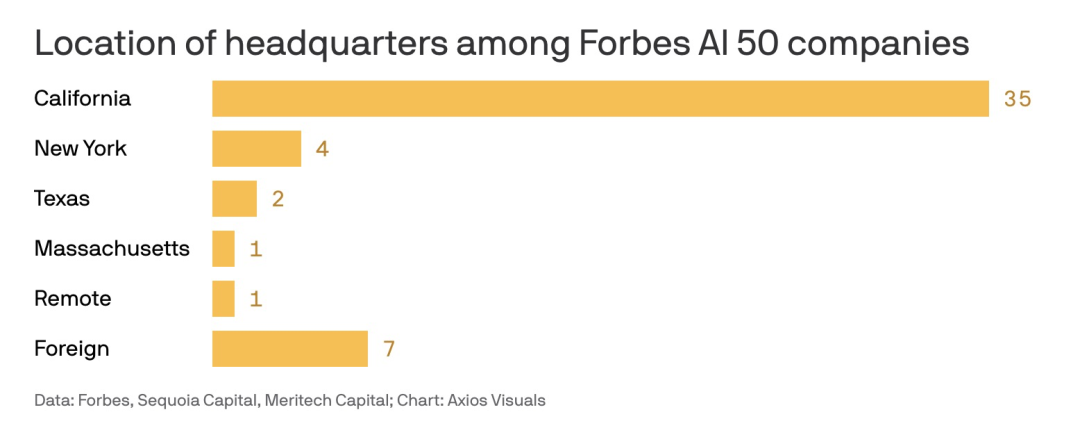
旱的旱死,涝的涝死日前,福布斯发布了人工智能50强名单:上榜的43家美国公司仅来自四个州,其中加利福尼亚州尤为突出,拥有高达35家公司;纽约州(4)、德克萨斯州(2)和马萨诸塞州(1),其中一家公司完全远程运营。没有一家位于铁锈地带、中西部或南部。
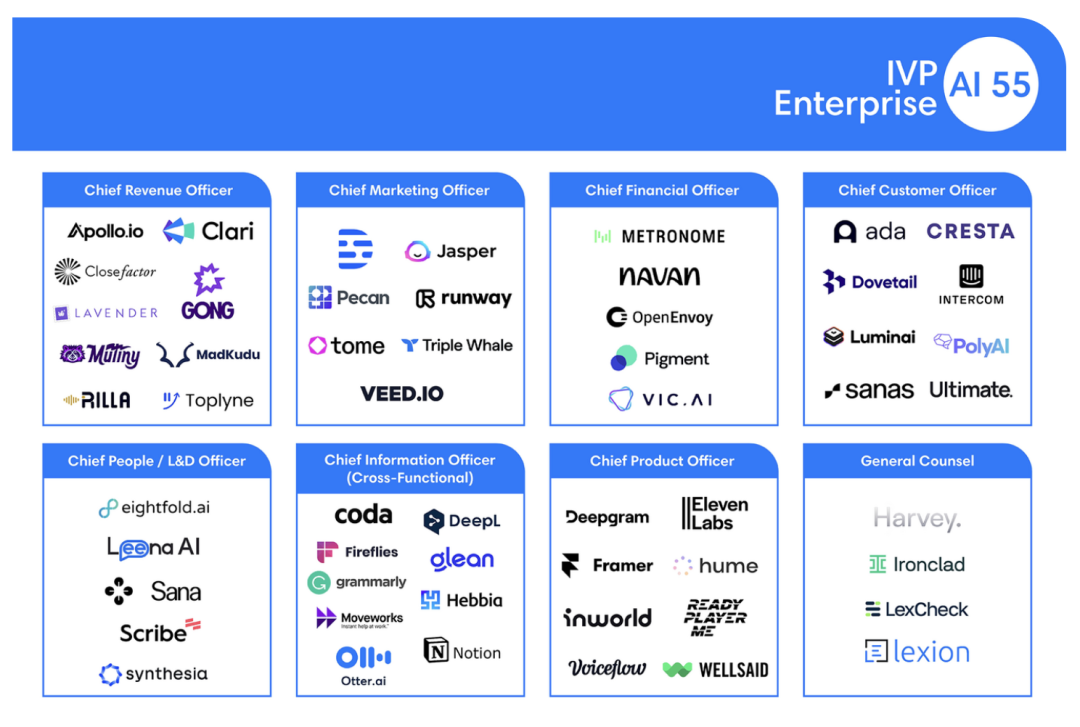
在其他AI榜单中,我们也可以看到这种高度的地理集中性。另一份IVP Enterprise 55名单中,有18名来自加州旧金山↓
美国顶级智库布鲁金斯学会近期发表了一则详尽的报告,通过对涵盖 384 个都市区人工智能研究和商业化七项指标的都市区数据进行聚类分析,发现美国的人工智能活动高度集中在“超级明星”——旧金山湾区(包含 SF metro与san jose metro),和13个“早期采用者”(early adopters)
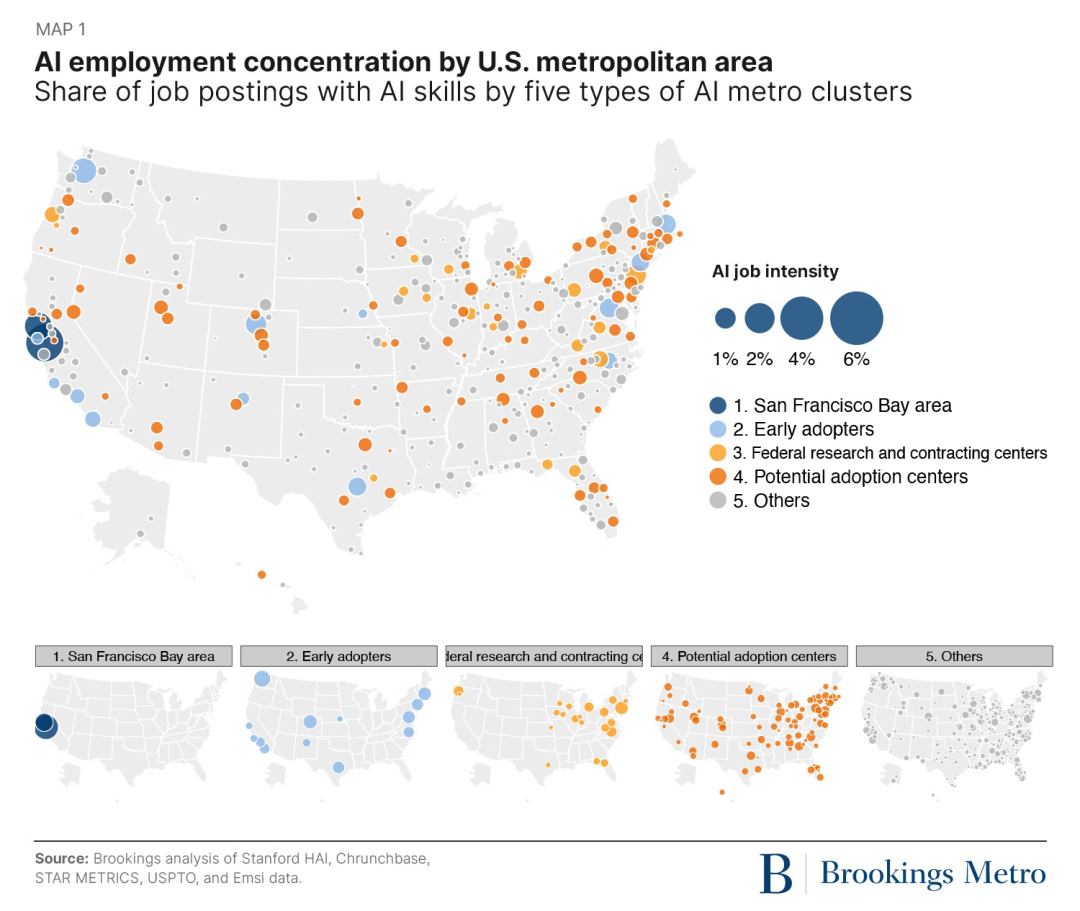
根据来自 Lightcast 的 2023 年 1 月至 2023 年 5 月的职位发布数据,60%的新生成式AI职位发布仅分布在上述15个都市区。同时在过去的 10 个月里,仅六个都市区(旧金山、圣何塞、纽约、洛杉矶、波士顿和西雅图)就占据了全美国生成式人工智能职位发布的近一半 (47%)。

 网络效应
网络效应在全球范围内,科技行业的就业在持续增长,但如果细细研究,就会发现——行业(尤其是科技行业)在地理分布上在继续集中,而不是“扩散”。
现在科技发展进入到“人工智能和机器学习”时代,特别是在早期阶段,更“需要”公司们集中在一起,而不是分散——公司的聚集不仅为公司们提供了更多的资源和机会,还加强了他们之间的合作和竞争关系。
UCB经济学教授恩里科·莫雷蒂(Enrico Moretti)长期研究城市经济学,在大量的研究后,他也得出了一个坚实的结论:美国的高科技产业越来越集中在少数昂贵的沿海城市。
在其著作《高薪城市》中,Enrico Moretti提到了一个现象——城市大分化(the Great Divergence)。核心观点是:
那些在企业家与科技驱动的创新经济上出色的城市赢得了人才与机会,并且由于马太效应,这种差距正在不断拉大,形成了“赢家通吃”的局面。
但是,能成为“赢家”的创新城市是少数。他们幸运地拥有“正确”的产业(集群),有坚实的人力资本基础,聚集着受过良好教育的劳动力和强大的创新生态,这些城市们在蓬勃成长,越来越大,创造出更多更好的工作岗位,吸引更多的高技能人才。

而且这些城市一旦成为“赢家”,就一直留在了牌桌上——
一项研究了过去20年的29项颠覆性技术的报告发现,这些高科技工作的分布仍然高度集中——比如,在计算机科学、半导体、生物化学排名前十的城市分别占据所有发明人总数的占 70%、79%和59%,而且常年保持领先。
这其中的原因之一就是坚韧的网络效应:
拿湾区来看。疫情期间,不少(打工)人、企业家都在策划“硅谷大逃离”——高企的房价、让人肉疼的生活成本、拥挤,堵车、不能忍的高犯罪率、不断蔓延的流浪汉问题、还有高税收……
但湾区作为全球技术和创新的中心,早已培育了一个强大坚韧的创新网络:这里有大量的技术公司、创业公司、风险投资机构和顶尖的研究机构——生态系统的价值来自于多个相互依赖的群体之间的交流互动。当生态系统的要素更加多元,互动也会更为复杂。
而你不得不承认的是,网络才是一个生态系统最难复制,也最容易“赢家通吃”,并且一直不下场的原因。
当然,在AI这个技术领域,还有一些独特的挑战。
首先它对人才的要求高。理论上说,只要有足够的专业知识,任何足够聪明的人都能做出生成式人工智能,无论他们是在湾区还是在上海。
其次,它需要海量的资金。训练人工智能模型需要大量的算力,这意味着海量的资金。
硅谷有着在人工智能研究领域的世界两所顶尖大学(斯坦福大学和加州大学伯克利分校)以及许多世界领先的人工智能研发投资者,包括 Alphabet、Facebook、Salesforce 和 NVIDIA——这个“大公司支持+顶级人才干活”的配方贡献了大量的2022年被引用次数最多的人工智能论文。
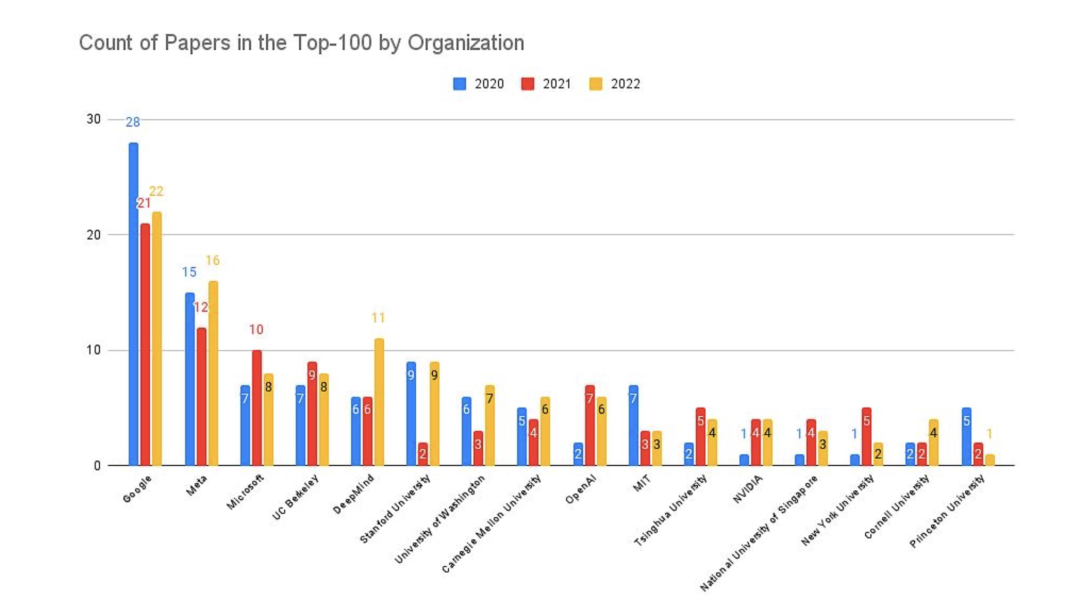
随着越来越多的AI公司在加利福尼亚州成立,这里形成了一个强大的网络效应。这种效应进一步加强了湾区在AI产业中的主导地位,使其成为科技公司和人才的首选地。

 “AI共同富裕”
“AI共同富裕”看起来,AI行业也将成为另一个高度集中、以湾区为中心的行业。
这时候,美国政府决定实行一下“AI共同富裕”,因为它认为:不平衡的分配可能会加剧社会不平等,导致某些地区的经济停滞。
方式就是——资助AI研究、提供教育和培训、制定有利于创新和公平竞争的政策来帮助更广泛的地区和人群受益于AI的好处。

自2020年以来,NSF已经在全国各地的大学建立了国家人工智能研究所的分布式网络。迄今为止,五年内总计投资近5亿美元,已在19个城市开展,帮助建立人工智能人才库,并与37个州建立了联系。

图片来源:https://www.nsf.gov/pubs/2023/nsf23610/nsf23610.pdf
美国的学术界越来越多地强调“基于地方的产业政策”的成功——毕竟之前美国政府发起的太空竞赛,就是一个政策导向的成功案例。
加上现在制造业回流美国,比如去年《芯片和科学法案》中包含的“区域技术和创新中心”计划,不少人意识到:
为了恢复美国工业基础的活力,就需要有更多的地方有基于AI的创新,如果人工智能更加集中,其他地区被边缘化,那工业基础也会受到负面影响。
所以第117届国会提出了800亿美元的“基于地方place based”的产业政策措施,其中包含了多项明确寻求改善国家高度集中的人工智能地理的投资计划。

美国版的产业政策
 AI + 行业
AI + 行业目前,生成式人工智能部署还处于早期阶段,但是速度非常快:技术和产业的深度融合正在全球范围内发生。生成式人工智能不再仅仅是提供信息内容服务的工具。它已经成为金融、医疗、自动驾驶等多个行业的“技术基座”,并有望成为未来社会的“技术基础设施”。
而中国在这方面的机遇和挑战都非常巨大。
在最近的2023中国算力大会上,不少专家表示:相对于以ChatGPT为代表的通用大模型,中国在这方面的短板相当明显:首先是起步较晚,技术积累和研发投入相对较少;另外不得不承认的是,通用大模型的训练需要大量的数据。尽管中国拥有庞大的互联网用户基数,但在多语言、多文化的数据收集和处理上,与国外的技术巨头相比还存在一定的差距。
不过,中国的机会在于行业大模型。
早在 2017 年,凯文·凯利就预测道:接下来的 10,000 家初创公司的公式是,你在某个行业已经在做一些东西,然后将人工智能添加到其中。重复一百万次,威力无穷。
I predict that the formula for the next 10,000 startups is that you take something and you add AI to it. We’re going to repeat that by a million times, and it’s going to be really huge.
行业大模型是专门为某个特定垂直行业设计的大型深度学习模型。行业特定的知识和经验可以被整合到模型中,从而提高模型的质量和准确性。
中国拥有世界上最完整的产业链和庞大的实体产业基础,从农业、制造业到服务业,涵盖了几乎所有的行业领域。这为行业大模型提供了丰富的应用场景和真实数据,使得模型能够更加贴近实际业务需求进行优化。
同时,中国的市场规模巨大,对于各种技术和产品都有着广阔的应用空间。行业大模型在中国有着巨大的市场潜力,无论是在传统行业的技术改造,还是新兴行业的创新发展中,都有着广泛的应用前景。
随着中国经济的转型升级,各行业都面临着技术改造和创新的压力。行业大模型作为一种能够为特定行业提供精准服务的技术,正好能满足这一需求。
比如随着制造业的自动化和精细化,传统的人工质检方式已经无法满足大规模生产线的需求。为了提高生产效率和产品质量,不少厂家开始利用计算机视觉和机器学习技术来开发智能质检模型。
其实在国内,已经逐步建立了涵盖理论方法和软硬件技术的体系化研发能力。例如,华为云盘古大模型已经在矿山、药物分子、电力、气象、海浪等领域推出了大模型,并在各行业中推出了超过1000个创新项目,助力人工智能技术与行业应用的深度融合。
基于通用大模型的基础能力,行业大模型已经成为技术发展的必然趋势。中国拥有庞大的实体产业基础,有着丰富的行业数据、对技术与产业深度融合的迫切需求、巨大的市场规模和快速的技术迭代能力。
这或许也是在大模型时代,中国产业在人工智能领域的机遇所在。